AWS DevOps Interview Questions: The Ultimate Guide for 2026
Master AWS DevOps interview questions with real-world answers on CI/CD pipelines, deployment strategies, CodeDeploy, CodePipeline, ECS, EKS, and zero-downtime deployments for 2026.
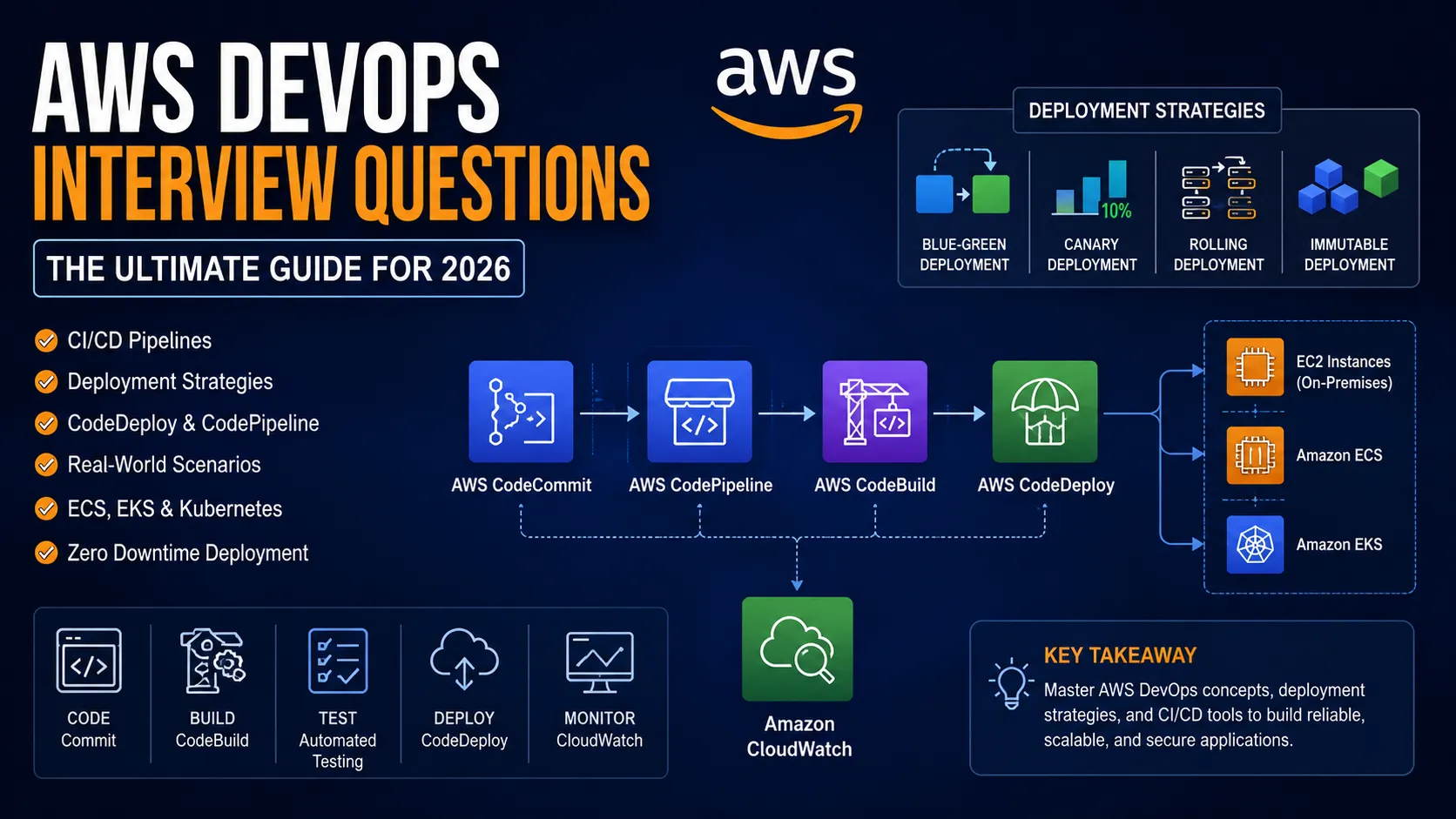
This guide answers the most important AWS DevOps interview questions asked in 2026. It covers CI/CD pipeline design, deployment strategies, AWS-native tooling, Kubernetes on EKS, infrastructure as code, and senior-level system design scenarios. Every answer reflects real production patterns, not vendor documentation summaries.
Whether you are preparing for a junior DevOps role or targeting a Staff or Principal Engineer position, the depth here matches what engineering managers and senior interviewers actually test.
Who Asks These Questions (and Why It Matters)
AWS DevOps interview questions appear across three distinct hiring contexts, and understanding which context you are interviewing in shapes how you should answer.
Product companies (fintech, SaaS, e-commerce) test for hands-on pipeline ownership. Interviewers often ask this to determine whether you have hands-on experience building, troubleshooting, and maintaining production deployment pipelines.
Consulting and services firms (TCS, Infosys, Wipro, Accenture) test breadth. TCS AWS DevOps interview questions, for example, tend to emphasize certification-level definitions alongside scenario-based problem-solving, because consultants must apply the same knowledge across multiple client environments.
Hyperscalers and cloud-native startups push hardest on system design, failure modes, and cost optimization under production constraints.
All three contexts share a common core, which this guide covers in full.
Foundational Concepts: The Vocabulary Filter
Before examining specific interview questions, establish the precise mental model that experienced interviewers use to screen candidates. Imprecise vocabulary is the first filter. Candidates who say "we used CodePipeline to deploy" when they mean CodeDeploy signal a shallow understanding of the service boundaries. Here are the distinctions that matter.
AWS CodePipeline is an orchestration service. It models a release workflow as a graph of stages and actions. It does not build code. It does not deploy code. It coordinates the services that do.
AWS CodeBuild is a build execution environment. It builds the application, executes automated tests, and generates deployment-ready artifacts.
It is stateless; each build runs in a fresh container.
AWS CodeDeploy is a deployment execution service. It deploys application artifacts to target environments such as EC2 instances, Lambda functions, and ECS task definitions. It manages deployment lifecycle hooks and traffic shifting.
Continuous Integration (CI) means every code commit triggers an automated build and test cycle. The goal is to catch integration errors within minutes, not days.
Continuous Delivery (CD) means every passing build produces a release candidate that can be deployed to production with a single action, often a manual approval gate.
Continuous Deployment means every passing build is automatically deployed to production without human intervention.
Knowing which of the three your current or prospective employer practices matters because it changes the risk tolerance, rollback requirements, and pipeline architecture you need to describe.
Core AWS DevOps Interview Questions
Q1: How does blue-green deployment differ from canary deployment, and when should each strategy be used?
This is the single most common AWS DevOps interview question. Interviewers ask it to test whether you understand traffic management, rollback mechanics, and risk mitigation simultaneously.
Blue-green deployment uses two fully replicated production environments to ensure smooth and low-risk releases. At any moment, one environment (blue) serves all live traffic. The updated application version is deployed to the inactive environment, commonly referred to as the green environment. When the green environment passes health checks, traffic shifts entirely from blue to green. The original blue environment remains active, providing a quick and reliable rollback option if issues arise.
Key characteristic: traffic switch is binary. 0% to 100% in a single operation.
Canary deployment releases a new version to a controlled fraction of production traffic, typically 5% to 10%, before gradually increasing that fraction. The name comes from the historical use of canaries in coal mines as early warning systems. A canary deployment is an early warning system for production failures.
Key characteristic: traffic shift is incremental. Error impact is proportional to the canary percentage at the time a failure occurs.
When to choose which:
Blue-green is preferable when rollback speed is the primary concern and the cost of running two full environments simultaneously is acceptable. It is the standard pattern for large, stateful applications where even a 5% error rate is unacceptable.
Canary deployment is preferable when blast radius reduction matters more than deployment speed, and when the application generates enough traffic that a 5-10% sample produces statistically meaningful error rate data within a few minutes.
AWS implementation:
AWS CodeDeploy supports both patterns natively. For Lambda and ECS targets, CodeDeploy traffic shifting configurations accept Canary10Percent5Minutes (shift 10% first, then all remaining traffic after 5 minutes) or Linear10PercentEvery1Minute (shift 10% per minute over 10 minutes). Blue-green for EC2 involves two Auto Scaling Groups behind an Application Load Balancer, with CodeDeploy managing the group swap.
Production example:
On a payment processing service running 24 ECS tasks across three Availability Zones, a canary configuration was set to shift 5% of traffic initially, hold for 15 minutes, and monitor a CloudWatch alarm tied to the 5xx error rate. If the alarm fired during the hold window, CodeDeploy automatically rolled back to the previous task definition. This configuration caught two regressions over six months that would each have resulted in complete service outages under a standard cutover deployment.
Q2: What is the difference between rolling deployment and immutable deployment?
This question is often asked immediately after discussions about blue-green and canary deployment strategies during DevOps interviews. Interviewers test your understanding of the mixed-version window problem and the cost-availability trade-off.
Rolling deployment updates instances in sequential batches. AWS Elastic Beanstalk, for example, replaces 25% of instances at a time by default (the batch size is configurable). During the update window, both old and new application versions handle requests simultaneously.
This creates two operational risks. First, if the old and new versions have incompatible API schemas or database migrations, some requests route to the wrong version. Second, if the deployment fails partway through, you have a partially updated fleet that requires manual remediation.
Rolling deployments are appropriate for stateless applications with backward-compatible changes where the cost of running a full duplicate environment is not justified.
Immutable deployment provisions a completely new set of instances running the new application version. Health checks run against the new fleet. Only after all new instances pass health checks does Elastic Beanstalk terminate the old fleet. At no point do old and new instances simultaneously serve production traffic.
The trade-off is cost: both fleets run for the duration of the health check window, roughly doubling compute costs temporarily. For an application where the deployment takes 8 minutes and runs on 20 EC2 instances, this is a measurable but manageable cost. For a 500-instance fleet, the economics matter more.
AWS Elastic Beanstalk deployment policies summary:
Policy | Mixed Version Window | Cost During Deployment | Rollback Mechanism |
|---|---|---|---|
All at once | No (but full downtime risk) | Baseline | Redeploy previous version |
Rolling | Yes | Baseline | Partial manual remediation |
Policy | Rollback Mechanism | Cost During Deployment | Rollback Mechanism |
|---|---|---|---|
Rolling with an additional batch | yes | Slightly above baseline | Partial manual remediation |
Immutable | NO | ~2x baseline temporarily | Terminate the new fleet |
Blue/green (swap URLs) | NO | ~2x baseline | Swap URLs back |
Q3: How do you achieve zero-downtime deployment on AWS?
Zero-downtime deployment is not a single technique. It is the combination of multiple mechanisms that collectively ensure at least one healthy application version always accepts user requests during a release.
The four required components:
Partial manual remediation
1. Load balancer connection draining. When an Application Load Balancer (ALB) deregisters an instance, it does not immediately drop existing connections. Connection draining (called "deregistration delay" in ALB terminology) allows in-flight requests to complete before the instance is removed. The default is 300 seconds; tuning this to match your application's P99 request latency prevents abrupt connection terminations.
2. Minimum healthy host enforcement. AWS CodeDeploy's deployment configuration includes a minimumHealthyHosts parameter. Setting this to a percentage (for example, 75%) means CodeDeploy will never simultaneously remove more than 25% of registered instances. This guarantees serving capacity throughout the deployment.
3. Health check gating. Both ALB target group health checks and CodeDeploy lifecycle hook health checks must validate that new instances are fully initialized before traffic routes to them. A common failure mode: an instance is marked healthy by the OS-level health check before the application has completed its startup sequence, resulting in 502 errors for the first 30-60 seconds after registration.
4. Pre-traffic and post-traffic hooks. For Lambda deployments, CodeDeploy supports BeforeAllowTraffic and AfterAllowTraffic hooks, which are Lambda functions that run validation logic before and after traffic shifts. Running a smoke test in BeforeAllowTraffic that validates the new function returns correct responses to a synthetic request prevents broken deployments from ever receiving production traffic.
The failure mode most candidates miss:
The original blue environment remains active, providing a quick and reliable rollback option if issues arise. An application can return HTTP 200 to a shallow /health endpoint while a database connection pool is still warming up or a cache is still being populated. Implement a "deep health check" endpoint that validates actual dependencies before responding 200. This is the difference between zero-downtime deployments in theory and zero-downtime deployments in production.
Q4: Explain the AWS CodeDeploy AppSpec file and lifecycle hooks.
The AppSpec file (appspec.yml) is the configuration artifact that CodeDeploy reads on each deployment target to understand what to do and when. It is the operational contract between your pipeline and your compute fleet.
For EC2/on-premises deployments, AppSpec defines the deployment lifecycle across these hooks in order:
ApplicationStop: Gracefully stop the current application version
DownloadBundle: CodeDeploy agent downloads the new revision from S3 or GitHub
Before Installation: Pre-installation tasks: backup files, create directories, set permissions
Install: Copy files to the final destination (defined in the files section)
After install: Post-installation tasks: configuration management, file permissions
ApplicationStart: Start the new application version
ValidateService: Run automated validation: port checks, smoke tests, health endpoint verification
The most important hooks for production reliability are BeforeInstall and ValidateService. BeforeInstall is where you implement graceful shutdown logic to drain in-flight requests. ValidateService is where you verify the new version is actually functioning before CodeDeploy marks the deployment as successful.
For ECS deployments, AppSpec references the new ECS task definition and container name, and defines BeforeAllowTraffic and AfterAllowTraffic Lambda hook functions. CodeDeploy handles the task replacement and ALB listener rule switching automatically.
A common AppSpec mistake: relying on exit codes incorrectly. CodeDeploy interprets any non-zero exit code from a lifecycle hook script as a deployment failure and triggers rollback. Scripts that intentionally exit non-zero for non-critical conditions (log rotation scripts that warn when no logs exist, for example) will cause deployment failures unless exit codes are explicitly handled.
Q5: How does AWS CodePipeline work, and how does it differ from Jenkins?
AWS CodePipeline is a managed, serverless pipeline orchestration service. You define a pipeline as a sequence of stages; CodePipeline manages state transitions, stores artifacts in S3 between stages, and integrates natively with AWS services, including CodeBuild, CodeDeploy, CloudFormation, Lambda, Elastic Beanstalk, and ECS.
Pipeline structure:
A standard production pipeline in CodePipeline contains:
Source stage: Detects a commit in CodeCommit, GitHub, Bitbucket, or an S3 bucket. Triggers the pipeline automatically via EventBridge.
Build stage: Invokes CodeBuild to compile, test, and package the application. Blue-green deployment uses two fully replicated production environments to ensure smooth and low-risk releases.
Test stage (optional): Integration tests, DAST scans, or load tests against a staging environment.
Approval stage (optional): A manual gate with SNS notification. Required before production promotion in regulated environments.
Deploy stage: Invokes CodeDeploy, CloudFormation, or a direct ECS service update.
How it differs from Jenkins:
Jenkins is a self-hosted, open-source automation server. It requires you to provision, operate, scale, and maintain the Jenkins controller and agent infrastructure.
CodePipeline is fully managed and serverless. There are no controllers to patch, no agents to scale, and no plugin compatibility issues. The trade-off is that CodePipeline is AWS-specific and less flexible for complex workflow patterns (parallel fan-out, dynamic stage generation, arbitrary conditional branching) that Jenkins handles natively.
Practical guidance for interviews:
Jenkins is appropriate when teams need extreme pipeline flexibility, multi-cloud portability, or have existing Jenkins investments. CodePipeline is appropriate when teams want zero operational overhead for the pipeline infrastructure itself and are committed to the AWS ecosystem.
Q6: What is infrastructure as code, and which tools does AWS support?
Infrastructure as code (IaC) is the practice of managing and provisioning cloud infrastructure through machine-readable configuration files rather than manual console operations. IaC makes infrastructure changes reviewable, versionable, testable, and repeatable.
AWS CloudFormation is the native AWS IaC service. It uses JSON or YAML templates to describe the desired infrastructure state. CloudFormation manages stacks (groups of related resources) and handles dependency resolution, rollback on failure, and drift detection. It is the deepest AWS integration available: CloudFormation supports every AWS service and often receives new service support before third-party tools.
AWS CDK (Cloud Development Kit) enables developers to define and manage cloud infrastructure using familiar programming languages such as TypeScript, Python, Java, C#, and Go. CDK synthesizes CloudFormation templates under the hood. CDK is preferable when teams are comfortable with programming languages and want to use logic, loops, and abstractions that YAML templates cannot express cleanly.
Terraform by HashiCorp is the most widely used multi-cloud IaC tool. It uses HCL (HashiCorp Configuration Language) and manages state in a backend (S3 with DynamoDB locking for AWS teams). Terraform supports AWS through a provider model and is the standard choice for teams operating across multiple cloud providers.
Key interview distinction:
CloudFormation is declarative and AWS-managed. You define the desired state; CloudFormation computes the diff and executes it. If CloudFormation encounters an error, it rolls back the entire stack to the last known good state. Terraform is also declarative but requires explicit state management. The Terraform state file must be stored, backed up, and locked carefully; state corruption is a real operational risk.
Q7: How do you manage secrets in an AWS DevOps pipeline?
This question tests security awareness as much as AWS knowledge. Interviewers listen for the explicit rejection of hardcoded credentials and environment variables containing sensitive values.
The correct answer in production:
AWS Secrets Manager stores secrets as versioned, encrypted key-value pairs. CodeBuild build environments retrieve secrets at runtime using the secretsManager parameter in the buildspec environment section, which injects the secret as an environment variable without it appearing in build logs or pipeline configuration.
AWS Systems Manager Parameter Store (SSM) is an alternative for configuration values and lower-sensitivity secrets. SecureString parameters in SSM are encrypted using KMS. SSM is less expensive than Secrets Manager but lacks automatic secret rotation.
Secret rotation:
Secrets Manager supports automated secret rotation for supported services, including RDS databases. A Lambda function (provided by AWS or customized) rotates the secret value on a defined schedule and updates the consuming application. This eliminates the operational burden of manual credential rotation.
IAM roles over IAM users:
CI/CD pipelines should authenticate to AWS using IAM roles, not IAM users with long-lived access keys. CodeBuild automatically assumes an IAM service role. EC2 instances use instance profiles. ECS tasks use task roles. Long-lived access keys in environment variables are a security anti-pattern that appears in a significant percentage of cloud security breaches.
Q8: What is Amazon ECS, and how does it differ from Amazon EKS?
Amazon ECS (Elastic Container Service) is AWS’s fully managed container orchestration platform designed to deploy, manage, and scale containerized applications. It manages the placement, scheduling, and lifecycle of Docker containers on either EC2 instances (ECS on EC2) or serverless compute (AWS Fargate). ECS uses its own proprietary API and integrates tightly with other AWS services: ALB, IAM, CloudWatch, Secrets Manager, and Service Discovery.
ECS is simpler to operate than Kubernetes. There is no control plane to manage, no etcd to back up, and no Kubernetes API server to maintain. For teams running containers primarily on AWS, ECS has a lower operational floor.
Amazon EKS (Elastic Kubernetes Service) is a fully managed AWS service that simplifies the deployment, management, and scaling of Kubernetes clusters.EKS runs the Kubernetes control plane (API server, etcd, scheduler) as a managed service. Teams manage worker nodes (EC2 instances or Fargate pods), kubectl configuration, and Kubernetes objects (Deployments, Services, ConfigMaps, Secrets).
EKS is more complex than ECS but provides portability. Kubernetes workloads can run on any managed Kubernetes service (GKE, AKS) or on-premises. This portability matters for organizations with multi-cloud strategies or on-premises Kubernetes requirements.
Deployment strategies in EKS:
Kubernetes uses rolling updates by default, controlled by maxSurge and maxUnavailable in the Deployment spec. For a blue-green pattern in Kubernetes, teams maintain two Deployment objects and switch the Service's label selector between them. For canary deployments, tools like Argo Rollouts or Flagger add progressive traffic-shifting capabilities to Kubernetes.
When to recommend which:
Recommend ECS when the team is small, AWS-native, and wants minimal operational overhead. Recommend EKS when the organization has existing Kubernetes expertise, multi-cloud requirements, or needs access to the broader Kubernetes ecosystem of tools (service meshes, GitOps operators, custom controllers).
Q9: How do you monitor a CI/CD pipeline on AWS?
Monitoring is a category that differentiates senior candidates. Knowing how to detect failure is as important as knowing how to deploy correctly.
Pipeline-level monitoring:
AWS CodePipeline publishes state change events to Amazon EventBridge. A pipeline entering a FAILED state triggers an EventBridge rule that can invoke a Lambda function, publish to an SNS topic, or post to a Slack channel via an API destination. Pipeline execution history is queryable via the CodePipeline API and visible in the AWS Console.
Build-level monitoring:
AWS CodeBuild publishes build metrics to CloudWatch: build duration, build success rate, and queue time. CloudWatch alarms on elevated build failure rates (for example, more than 3 failures in 10 minutes) provide early warning of broken CI configuration or upstream dependency failures.
Application-level monitoring post-deployment:
Deployment health is monitored through CloudWatch metrics on the target compute layer. For ECS services: CPUUtilization, MemoryUtilization, task count, and ALB target group health check failure rates. For Lambda: error rate, throttle rate, and P99 duration. CodeDeploy canary deployments can be configured with CloudWatch alarm triggers that automatically roll back a deployment if an alarm fires during the traffic-shifting window.
The answer interviewers want to hear:
Do not stop at "we used CloudWatch." Describe a specific alarm, what metric it monitored, what threshold triggered it, what action it took, and what production failure it caught or prevented. A concrete failure story demonstrates production experience more effectively than a list of service names.
Q10: What is a DevOps Engineer's role during an incident?
This question is common in senior AWS DevOps interviews and often determines whether candidates get offers at the Staff Engineer level. It tests incident response process knowledge, communication practices, and post-incident learning.
During a production incident:
The on-call DevOps engineer owns the deployment pipeline as a suspect and a recovery tool simultaneously. First action: determine whether a recent deployment correlates with the incident start time. CloudWatch metrics and CodeDeploy deployment history provide this correlation quickly.
If a recent deployment is confirmed as the cause, the fastest recovery path is rollback, not forward fix. CodeDeploy rollbacks are triggered in seconds from the console or CLI. For ECS services, rolling back to the previous task definition revision is a single API call.
If no recent deployment is implicated, the DevOps engineer focuses on infrastructure: Auto Scaling Group state, ALB target group health, EC2 or ECS instance health, and CloudWatch metric anomalies.
Post-incident:
A blameless post-mortem examines the timeline, identifies contributing factors, and produces actionable remediation items. For DevOps engineers specifically, post-mortems typically generate pipeline improvements: tighter canary hold windows, additional smoke tests in ValidateService hooks, or new CloudWatch alarms for failure modes that were not previously monitored.
Advanced Topics: What Senior-Level Questions Test
Infrastructure as Code Drift Detection
AWS CloudFormation drift detection identifies when a resource's actual configuration differs from its CloudFormation template definition. Running drift detection after every deployment ensures that out-of-band manual changes have not created hidden configuration debt. Automated drift detection on a schedule, triggered by EventBridge and reported to a Slack channel, is a production best practice that interviewers at senior levels expect candidates to describe.
GitOps on EKS
GitOps is a deployment model where a Git repository is the single source of truth for infrastructure and application state. A reconciliation operator (ArgoCD or Flux) continuously compares the desired state in the Git repository with the actual state in the Kubernetes cluster and automatically corrects drift.
In an EKS GitOps architecture, developers commit Kubernetes manifests to a Git repository. ArgoCD detects the commit, computes the diff against the cluster, and applies the change. There is no direct kubectl access to the production cluster; all changes flow through Git, providing a complete, auditable change history.
Multi-Region Deployment
Senior candidates should describe a multi-region deployment architecture: a primary region runs the active deployment pipeline; Route 53 geolocation or latency-based routing distributes traffic across regions; CodePipeline cross-region actions deploy to multiple regions in parallel or sequentially. RDS global databases or DynamoDB global tables handle data replication.
What TCS and Other Consulting Firms Test Specifically
TCS AWS DevOps interview questions frequently combine definition-level questions with scenario-based problem solving. A typical TCS DevOps interview includes:
Definitions with distinction: "What is the difference between CodeBuild and CodeDeploy?"
Process questions: "Walk me through the steps CodeDeploy takes when executing a blue-green deployment on ECS."
Scenario questions: "A deployment fails at the ValidateService hook. What are the possible causes, and how do you diagnose each?"
Architecture Scenario: Design a CI/CD pipeline for a three-tier web application that includes dedicated staging and production environments.
For consulting interviews, the breadth of AWS service knowledge matters alongside depth. Be prepared to name relevant services for monitoring (CloudWatch, X-Ray, AWS Config), security (GuardDuty, Security Hub, IAM Access Analyzer), and networking (VPC, Transit Gateway, AWS PrivateLink), even if they are not your primary expertise.
Common Mistakes That Cost Candidates Offers
Using service names interchangeably. Saying "CodePipeline deploys the code" when CodeDeploy is the deploying service signals shallow experience.
Describing deployments without mentioning failure. Every deployment story should include: what could go wrong, how you detect it, and how you recover. Deployments are only as good as their rollback paths.
Ignoring cost. Senior interviewers ask about cost optimization. Immutable deployments have higher costs than rolling deployments. Blue-green deployments require double the compute capacity during the transition window. Acknowledge these trade-offs and describe how you mitigated them (for example, using Spot Instances for the idle blue fleet).
Not mentioning IAM. Every AWS architecture discussion should include IAM role assignment. Forgetting to address who has permissions to do what signals a candidate who has not run production workloads.
Generic monitoring answers. "We used CloudWatch" is incomplete. Name the specific metrics, alarm thresholds, and actions your monitoring drove.
Deployment Strategy Comparison: Quick Reference
Strategy | Downtime Risk | Rollback Speed | Blast Radius | Cost Impact | Primary AWS Service |
|---|---|---|---|---|---|
Blue-green | None | Instant | Zero | High (2x compute) | CodeDeploy, ALB |
Canary | Very low | Fast | Proportional to % | Low | CodeDeploy traffic shifting |
Strategy | Downtime Risk | Rollback Speed | Blast Radius | Cost Impact | Primary AWS Service |
|---|---|---|---|---|---|
Rolling | Low | Moderate | Moderate | Baseline | Elastic Beanstalk, CodeDeploy |
Immutable | None | Fast | Zero | Moderate (temporary) | Elastic Beanstalk |
All-at-once | High | Redeploy required | Full | Baseline | Any |
AWS DevOps Certification Context
The AWS Certified DevOps Engineer – Professional certification validates the knowledge required for senior DevOps roles. It covers CI/CD, configuration management, monitoring and logging, policies and standards automation, and incident and event response.
As preparation context: the exam tests deeper knowledge than standard interview questions require, particularly around AWS Config rules, Systems Manager automation documents, and cross-account pipeline patterns. Studying for the certification builds vocabulary and mental models that interviewers reward even if they do not ask certification-level questions directly.
conclusion
Every strong answer to an AWS DevOps interview question follows a consistent structure:
Define the concept precisely, distinguishing it from adjacent concepts.
Explain the trade-offs — no deployment strategy, tool, or architecture pattern is universally optimal. Articulating trade-offs signals engineering judgment.
Describe a production scenario — even if you have to frame it as "in a project I worked on" or "the approach I would take," grounding abstract concepts in concrete systems demonstrates readiness.
Address failure modes — how does the system behave when a deployment fails, a pipeline breaks, or a canary triggers an alarm? Recovery design separates engineers who have operated production systems from those who have only studied them.
The AWS DevOps engineering discipline is fundamentally about reliable change delivery. Interviewers test whether you think about deployment as a series of safety mechanisms around a risky operation, not as a mechanical sequence of automated steps. Engineers who internalize that framing consistently perform better in technical interviews and, more importantly, in production.
Frequently Asked Questions
Q: What topics do AWS DevOps interviews cover in 2026?
AWS DevOps interviews cover CI/CD pipeline design, deployment strategies (blue-green, canary, rolling, immutable), AWS-native services (CodePipeline, CodeBuild, CodeDeploy, ECS, EKS), infrastructure as code (CloudFormation, Terraform, CDK), secrets management, monitoring and observability, IAM and security practices, and, for senior roles, system design, incident response, and cost optimization.
Q: What are the top DevOps interview questions candidates are most likely to encounter in 2026?
The most frequently asked questions involve deployment strategy trade-offs (blue-green vs. canary), zero-downtime deployment mechanics, CodeDeploy lifecycle hooks, pipeline orchestration with CodePipeline, container deployment on ECS and EKS, and infrastructure as code with CloudFormation or Terraform.
Q: How do I answer TCS AWS DevOps interview questions?
TCS interviews combine definition questions with scenario-based problem-solving. Prepare clear, concise definitions for all core services, practice walking through deployment lifecycle steps end-to-end, and be ready to diagnose hypothetical failure scenarios. TCS interviews also test breadth of AWS service knowledge, so familiarity with monitoring, networking, and security services alongside core DevOps tooling is valuable
Q: How does AWS CodeDeploy differ from AWS CodePipeline, and when should each service be used?
CodePipeline is a pipeline orchestration service that models and manages the entire software release workflow from source commit to deployment. CodeDeploy is a deployment execution service that moves application artifacts onto compute targets (EC2, Lambda, ECS). CodePipeline calls CodeDeploy as one action within a larger pipeline. CodeDeploy can also be used independently without CodePipeline.
Q: What is a zero-downtime deployment on AWS, and how is it achieved?
A zero-downtime deployment releases new software without any interruption to end users. AWS achieves this through ALB connection draining (which allows in-flight requests to complete before instance removal), minimum healthy host enforcement in CodeDeploy, blue-green or immutable deployment strategies that never remove the only healthy instance fleet, and health check gating that prevents traffic routing to uninitialized instances.
Q: What AWS certification is most relevant for DevOps roles?
The AWS Certified DevOps Engineer – Professional is the primary credential. It validates knowledge of CI/CD, configuration management, monitoring, and incident response on AWS. Many hiring managers also value the AWS Certified Solutions Architect – Associate for evidence of broader architectural reasoning. Certifications signal structured knowledge, but hands-on pipeline and deployment experience carries more weight in technical interviews.
Q: How should I prepare for AWS DevOps interview questions on deployment strategies?
Study each strategy: blue-green, canary, rolling, and immutable until you can explain trade-offs clearly without notes. Practice describing a real or realistic production scenario for each. Use the AWS Free Tier to configure a CodeDeploy deployment end-to-end, including a lifecycle hook script, so you can speak from direct experience. Draw architecture diagrams showing ALB, Auto Scaling Groups, and target groups for each strategy.
Share this article
Related Articles

10 Study Hacks That Help Students Learn Faster, Remember More, and Score Higher in 2026
Learn 10 science-backed study hacks that help students study smarter, retain information longer, stay focused, and perform better in exams.

How Ed-Tech Uses Gamification to Boost Learning
Research confirms that gamification works. Students in gamified environments show 14% higher long-term knowledge retention, and gamified online courses achieve 30–40% better completion rates than non-gamified equivalents. Meanwhile, 89% of students say they would spend more time learning if tools felt more like games a number that explains why every major ed-tech platform from Duolingo to Khan Academy has gamification at its core.

How Does Ed-Tech Support Flipped Classrooms? The Complete 2026 Guide
The flipped classroom model reverses traditional instruction: students learn new content at home via digital tools, then apply knowledge in class through collaborative activities. Ed-tech makes this possible through Learning Management Systems (LMS), video-based learning platforms, adaptive learning tools, and formative assessment software. This guide covers every mechanism, top platform recommendations, research data, and real implementation strategies educators can use immediately.


